DistributedDataParallel non-floating point dtype parameter with requires_grad=False · Issue #32018 · pytorch/pytorch · GitHub
🐛 Bug Using DistributedDataParallel on a model that has at-least one non-floating point dtype parameter with requires_grad=False with a WORLD_SIZE <= nGPUs/2 on the machine results in an error "Only Tensors of floating point dtype can re

Torch 2.1 compile + FSDP (mixed precision) + LlamaForCausalLM

Rethinking PyTorch Fully Sharded Data Parallel (FSDP) from First
If a module passed to DistributedDataParallel has no parameter

Inplace error if DistributedDataParallel module that contains a
Don't understand why only Tensors of floating point dtype can
AzureML-BERT/pretrain/PyTorch/distributed_apex.py at master
Pytorch 並列 DataParallel/DistributedDataParallelについて - 適当な

Torch 2.1 compile + FSDP (mixed precision) + LlamaForCausalLM
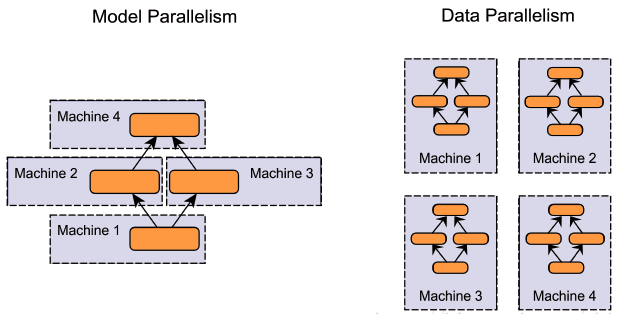
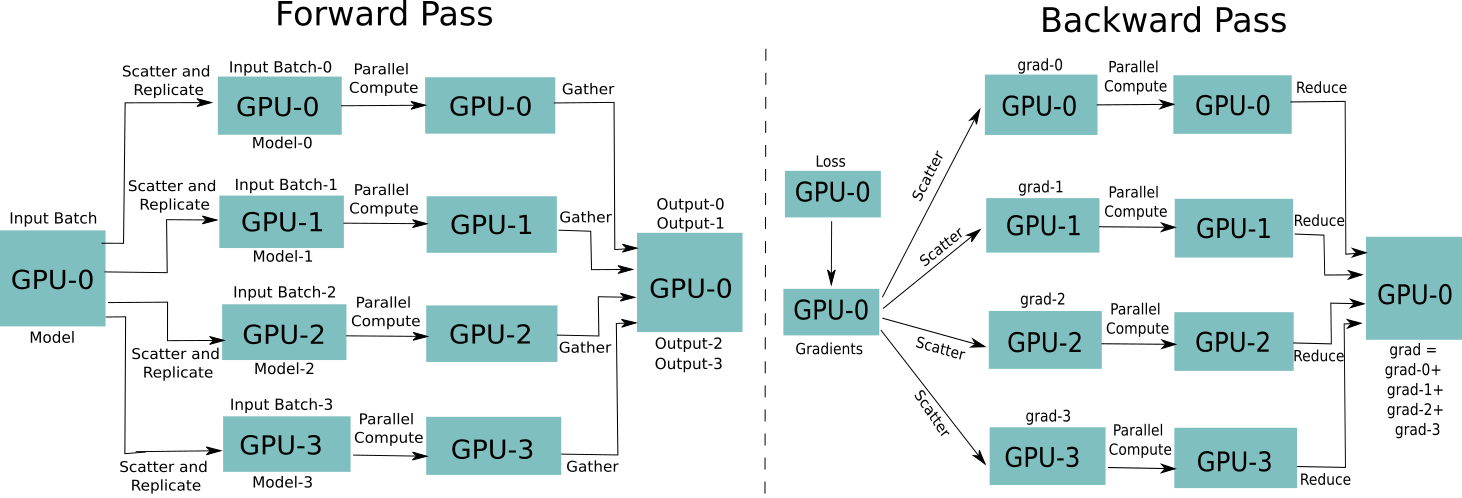
Distributed Data Parallel and Its Pytorch Example
Don't understand why only Tensors of floating point dtype can
Cannot update part of the parameters in DistributedDataParallel







